
library(tidymodels) # for the parsnip package, along with the rest of tidymodels
# Helper packages
library(tidyverse) # for data manipulations
library(conflicted) # for helping with conflicts
library(skimr) # for nice data summaries
library(ranger) # needed for our random forests
library(gt) # for tables
library(usemodels) # for generating nice boilerplate code
library(vip) # for variable importance of random forest
conflicts_prefer(dplyr::filter)
conflicts_prefer(modeldata::penguins)Modelling in R
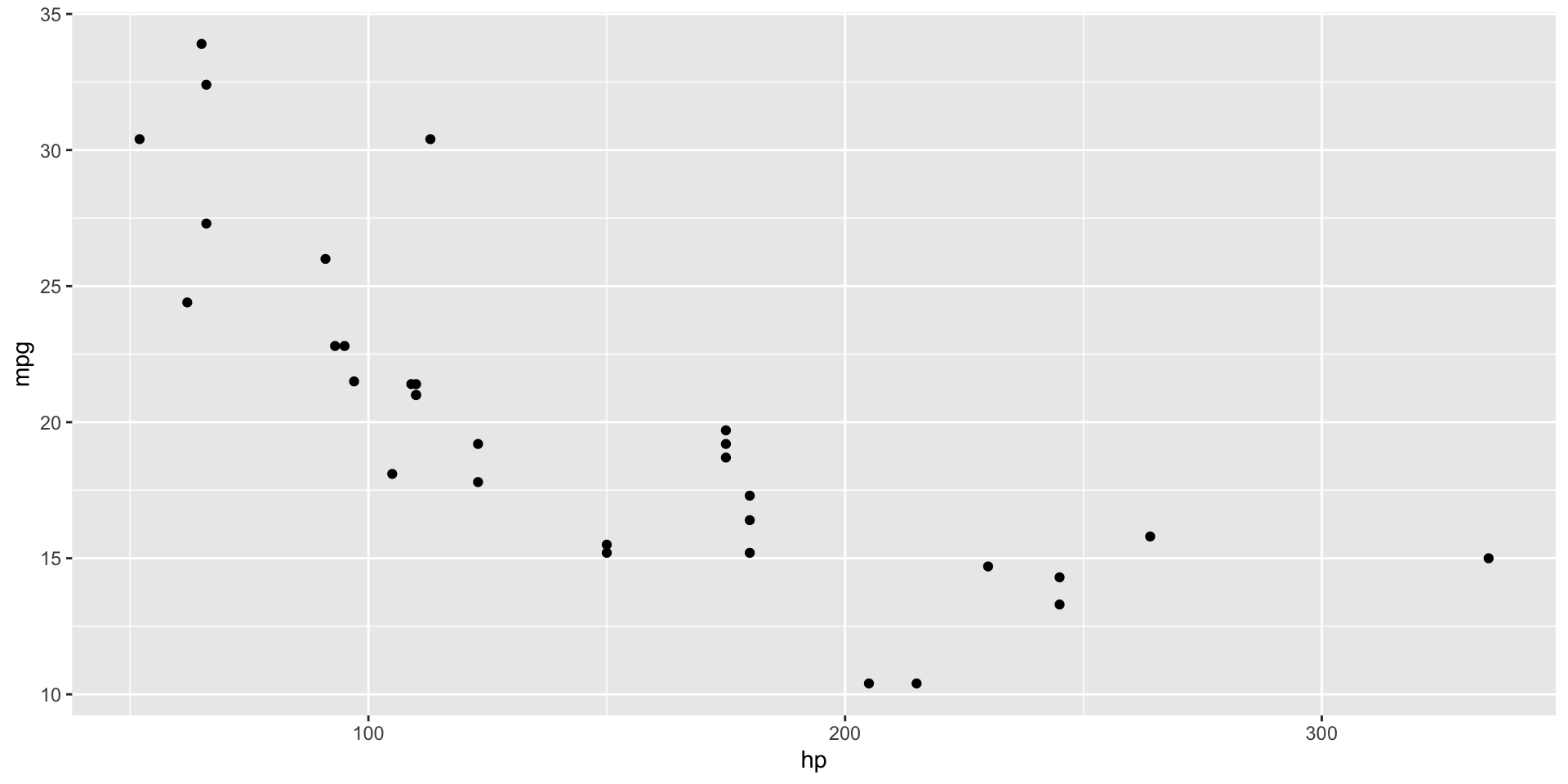
Plot data
- Plotting our data is always a good first step
- Do you see an obvious trend?
Models - line of best fit
- You’ve seen how we can add a line to the data before, but what does it mean?
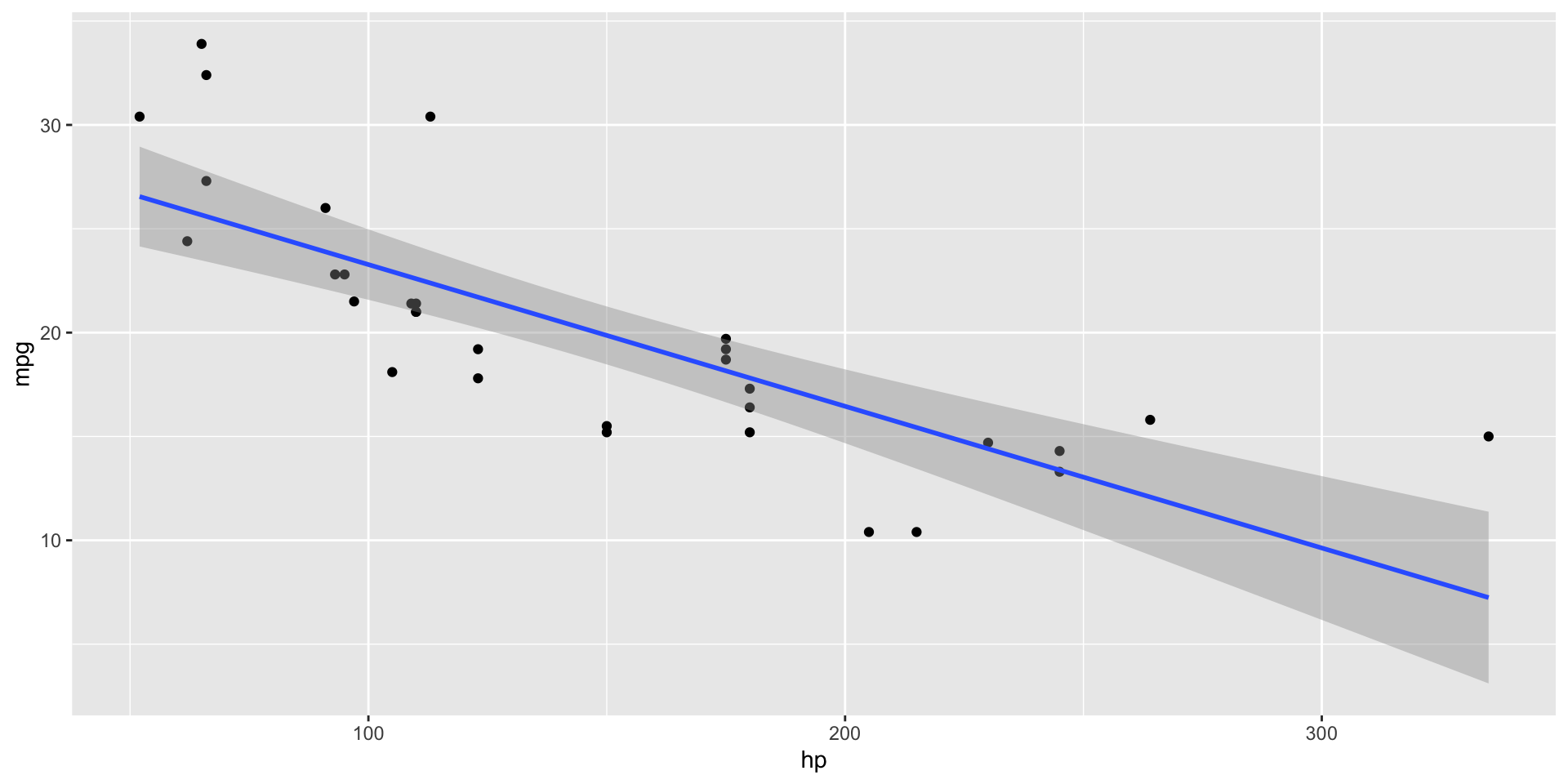
Visualising Model Fitness
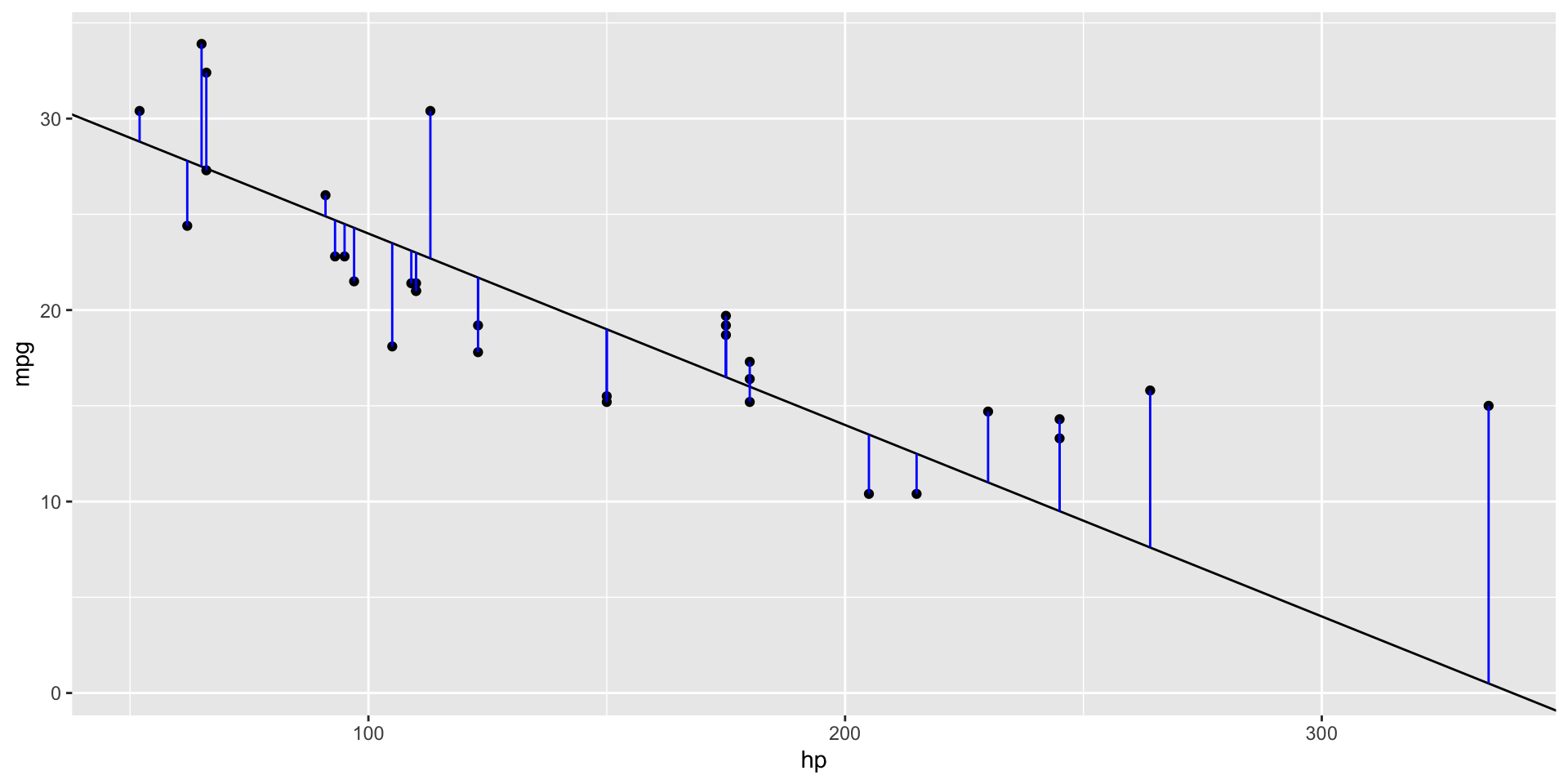
An example with the Palmer penguins dataset
- Observations of Antarctic penguins who live on the Palmer Archipelago
- Let’s have a quick look at the data
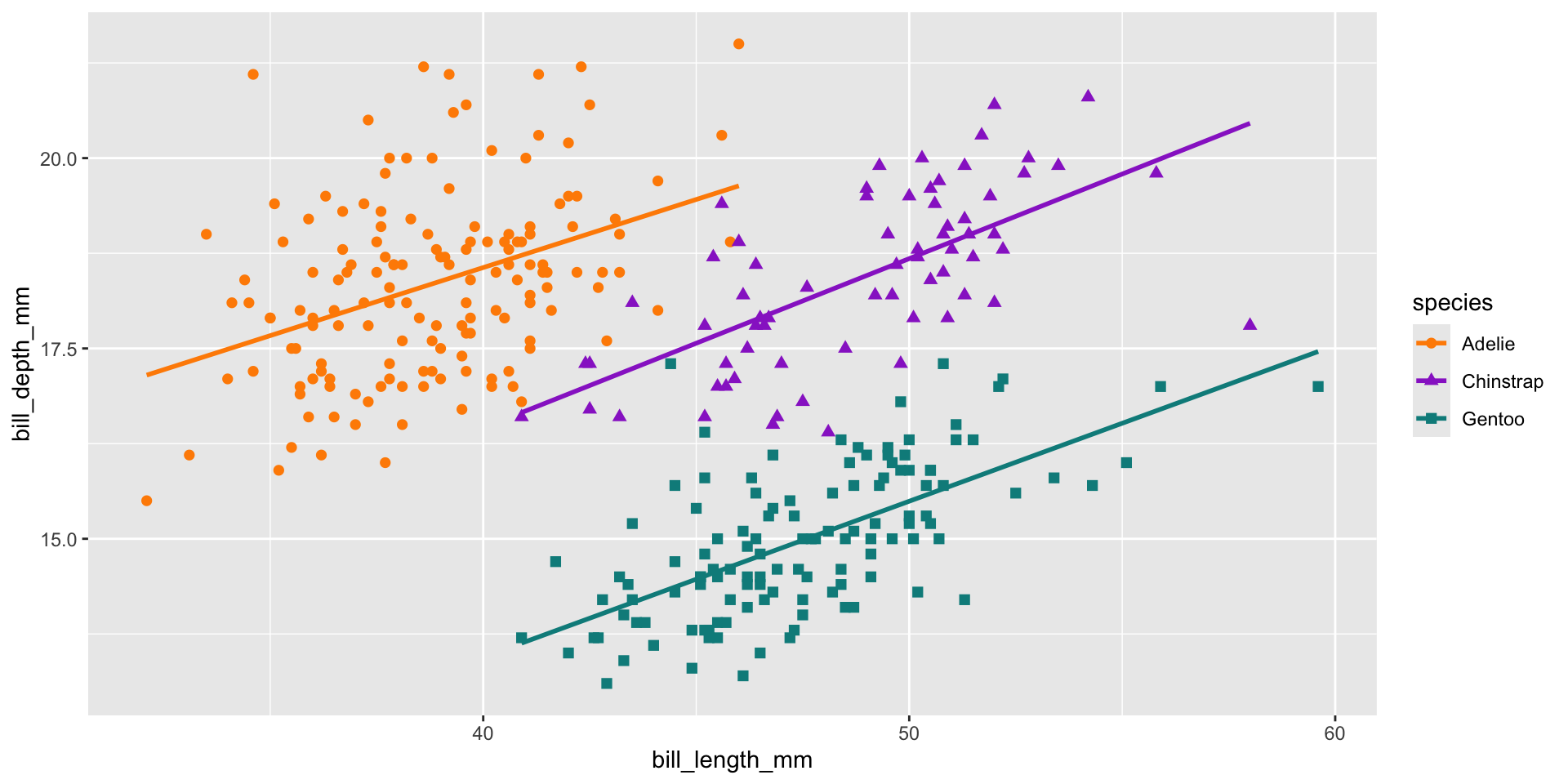
- It looks like there’s a slight negative correlation between bill length and depth right…?
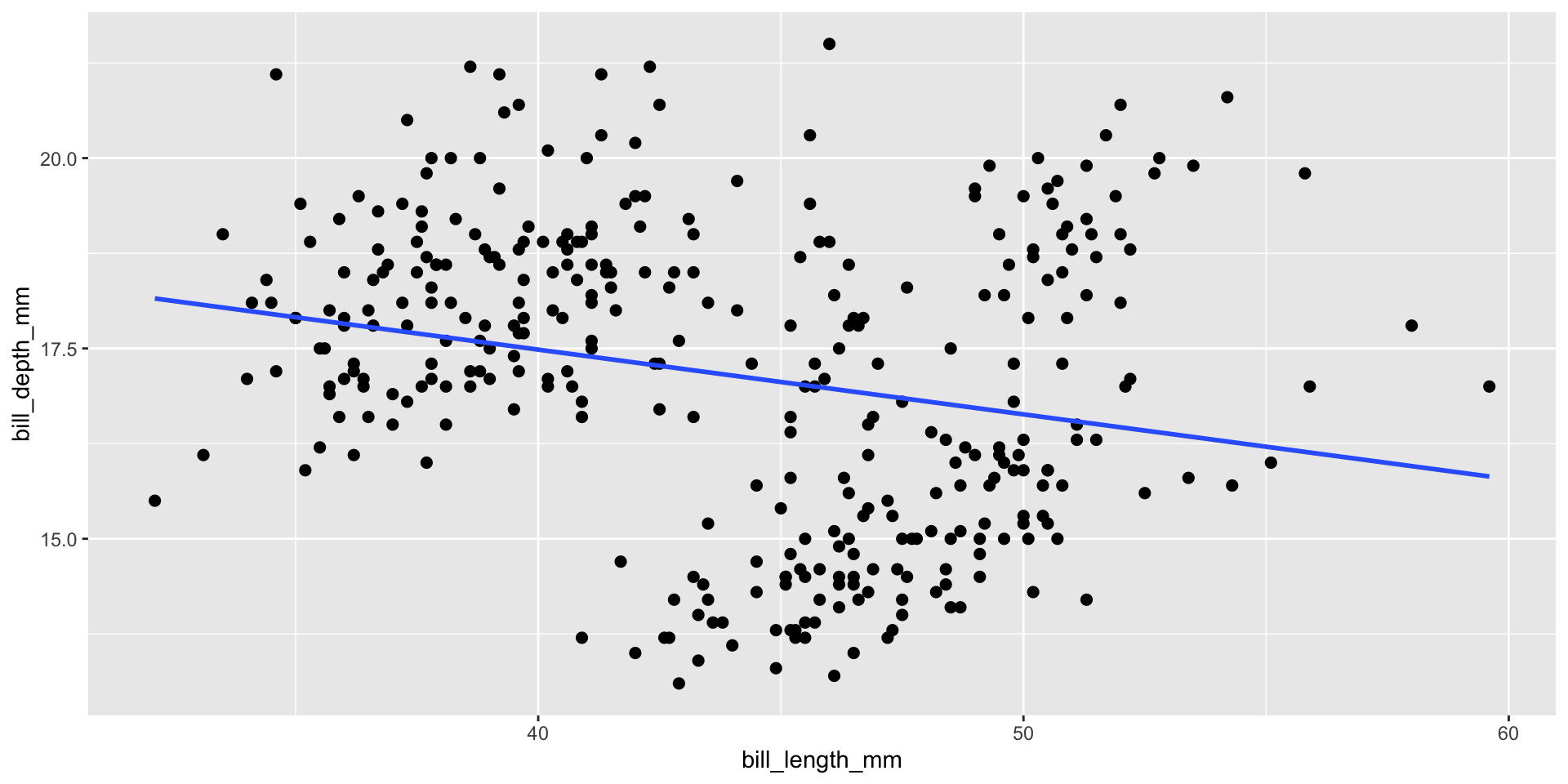
Think carefully about your data!
- We have 3 different species in this data, what happens if we check those?
- A nice example of Simpson’s paradox
Building a model with tidymodels
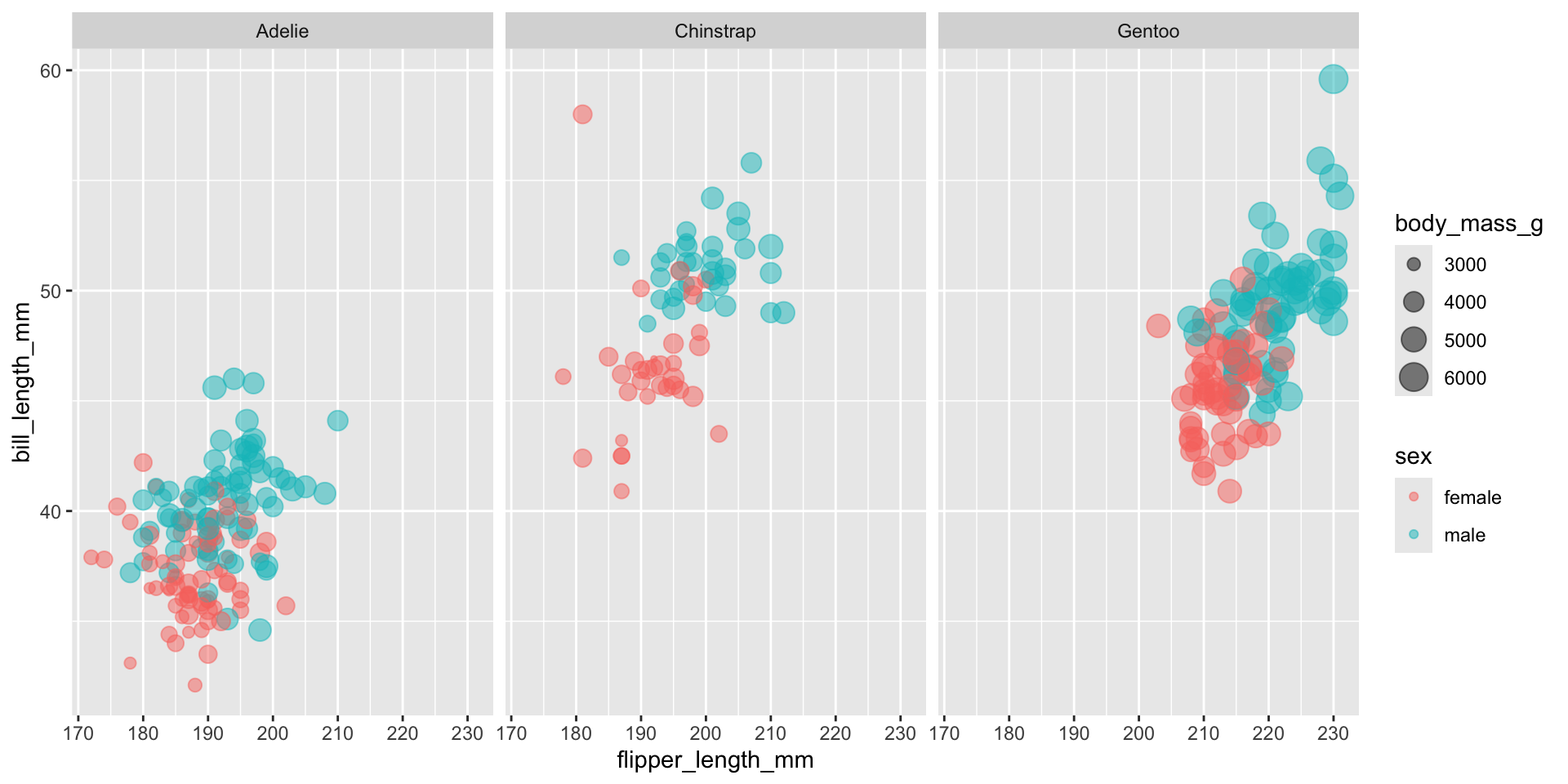
- Let’s say we want to try and predict the sex of a penguin based on it’s physical characteristics
Visualising different hyperparameters
# A tibble: 5 × 8
mtry min_n .metric .estimator mean n std_err .config
<int> <int> <chr> <chr> <dbl> <int> <dbl> <chr>
1 1 14 accuracy binary 0.920 25 0.00550 Preprocessor1_Model01
2 2 2 accuracy binary 0.918 25 0.00571 Preprocessor1_Model03
3 1 31 accuracy binary 0.915 25 0.00581 Preprocessor1_Model02
4 2 18 accuracy binary 0.914 25 0.00522 Preprocessor1_Model04
5 3 6 accuracy binary 0.910 25 0.00525 Preprocessor1_Model06# A tibble: 5 × 8
mtry min_n .metric .estimator mean n std_err .config
<int> <int> <chr> <chr> <dbl> <int> <dbl> <chr>
1 2 2 roc_auc binary 0.979 25 0.00195 Preprocessor1_Model03
2 1 14 roc_auc binary 0.977 25 0.00220 Preprocessor1_Model01
3 2 18 roc_auc binary 0.976 25 0.00211 Preprocessor1_Model04
4 3 6 roc_auc binary 0.976 25 0.00203 Preprocessor1_Model06
5 1 31 roc_auc binary 0.975 25 0.00236 Preprocessor1_Model02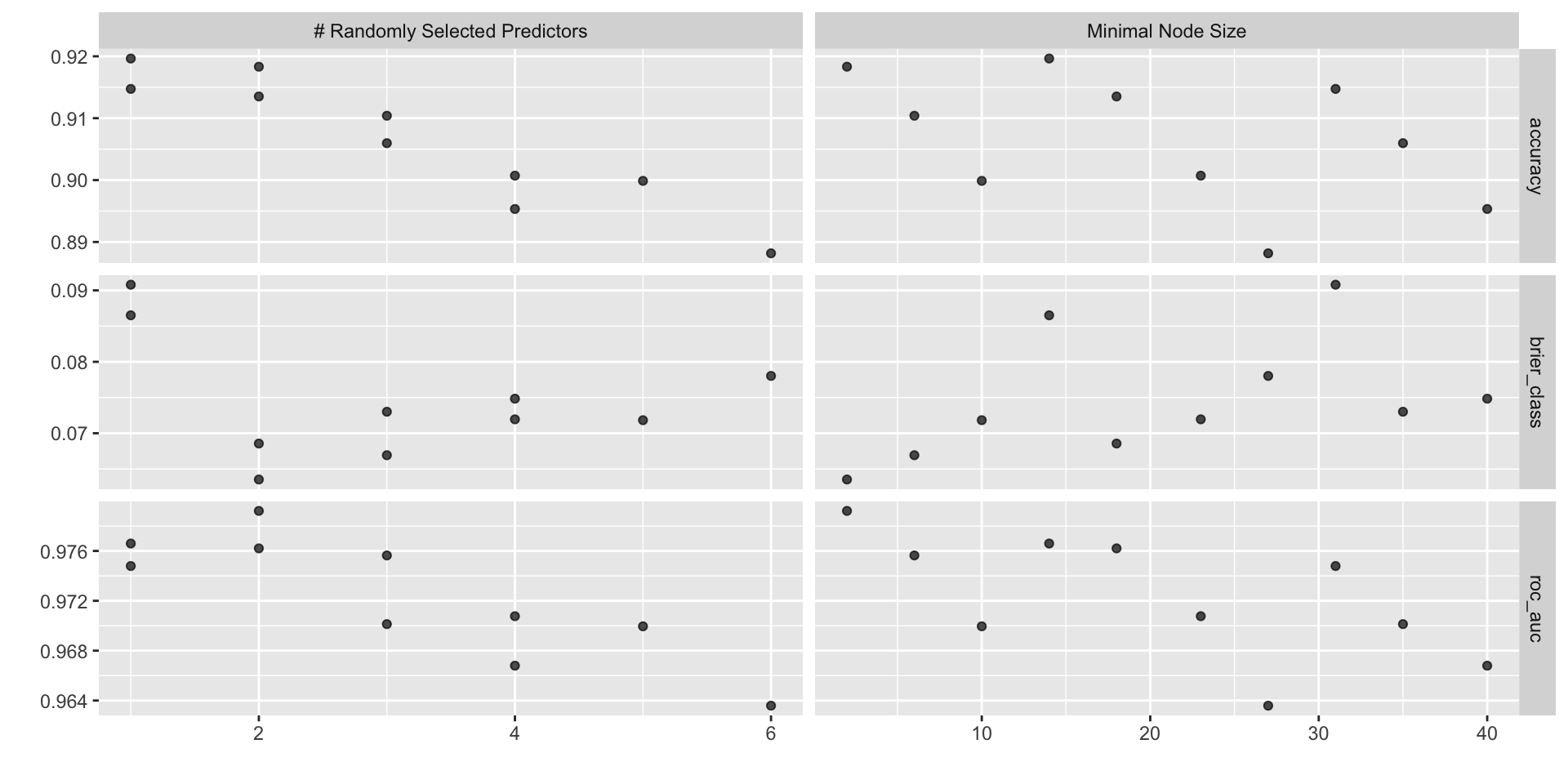
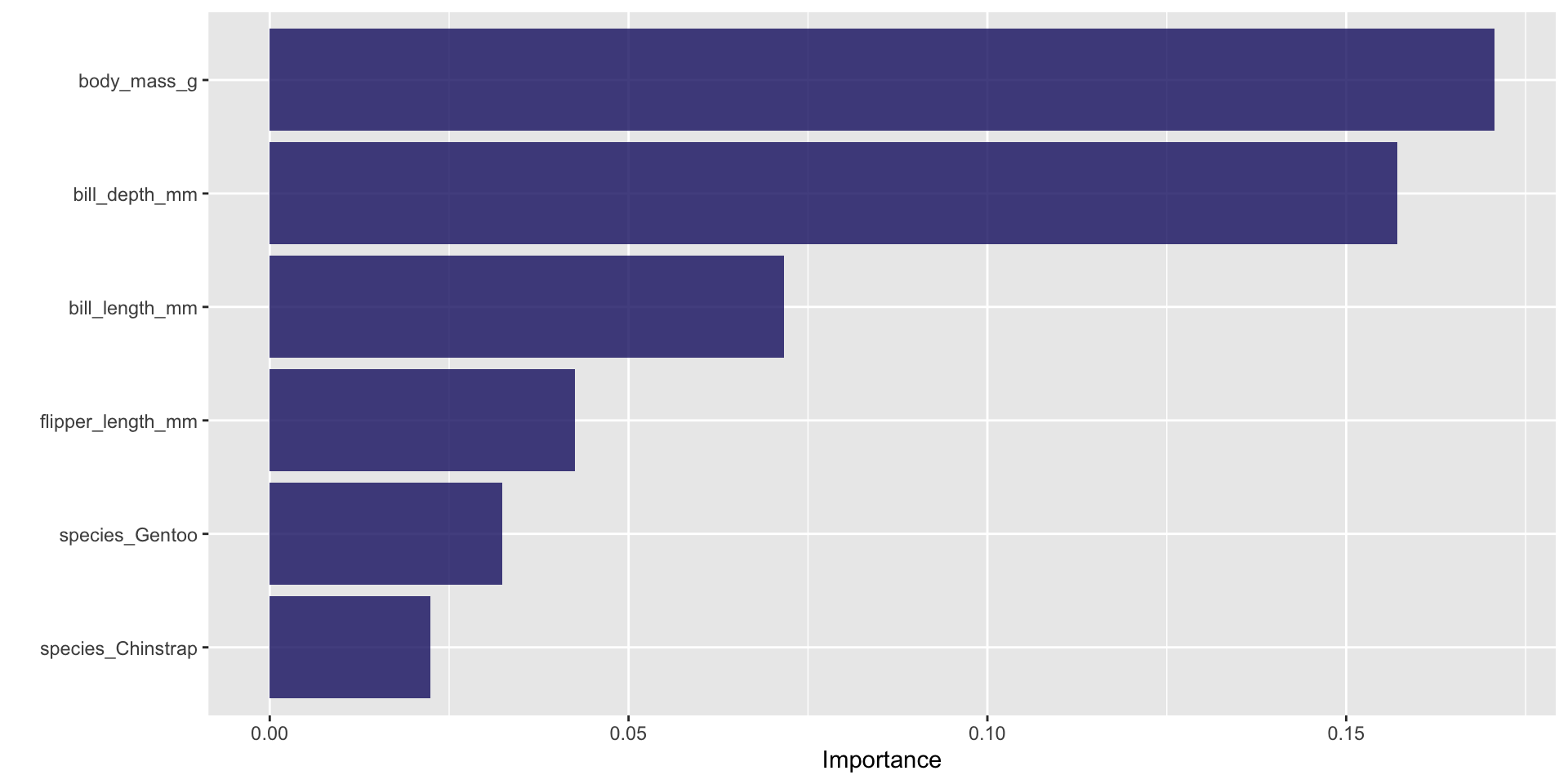
Random forest variable importance
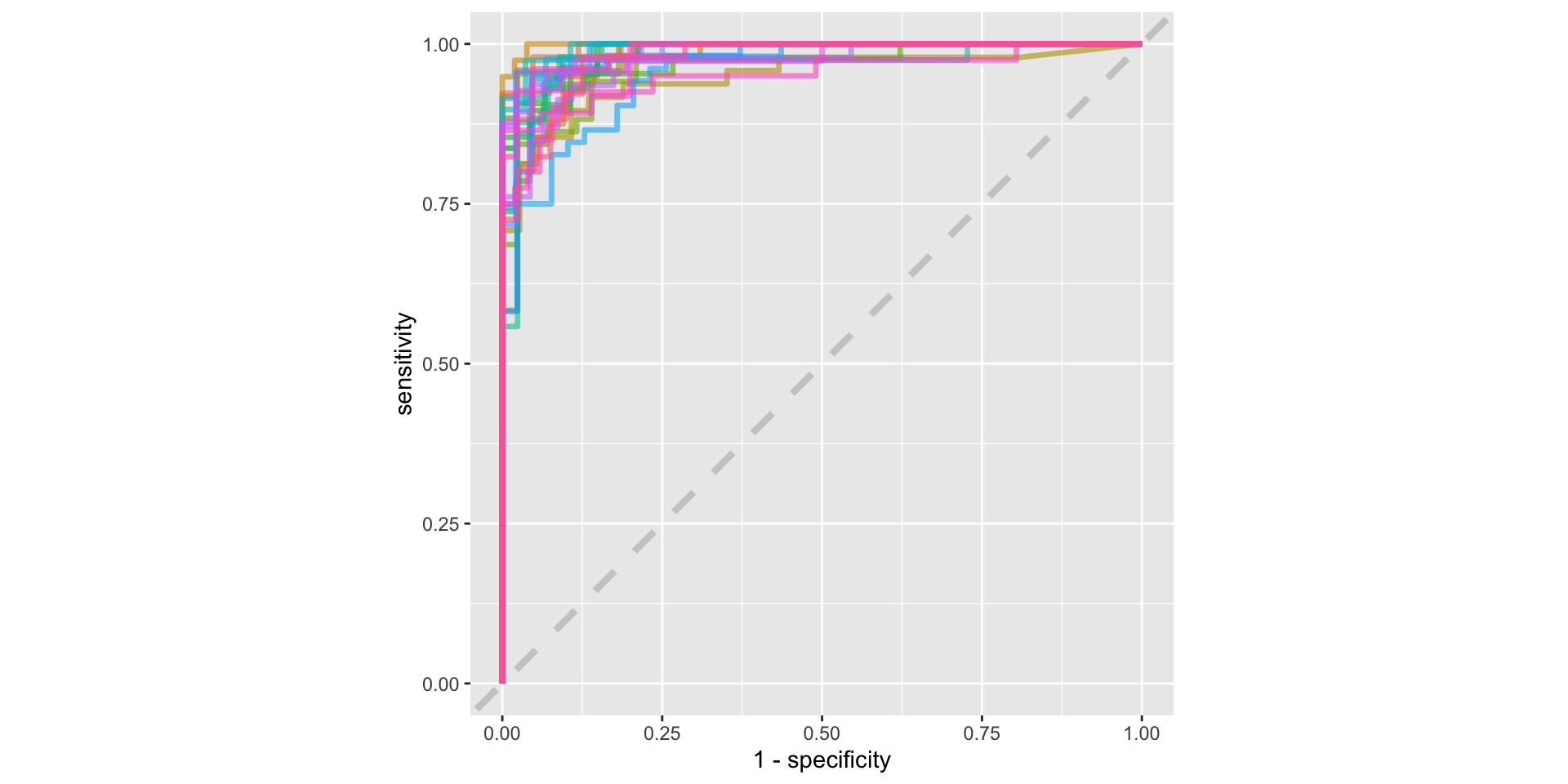
ROC curve
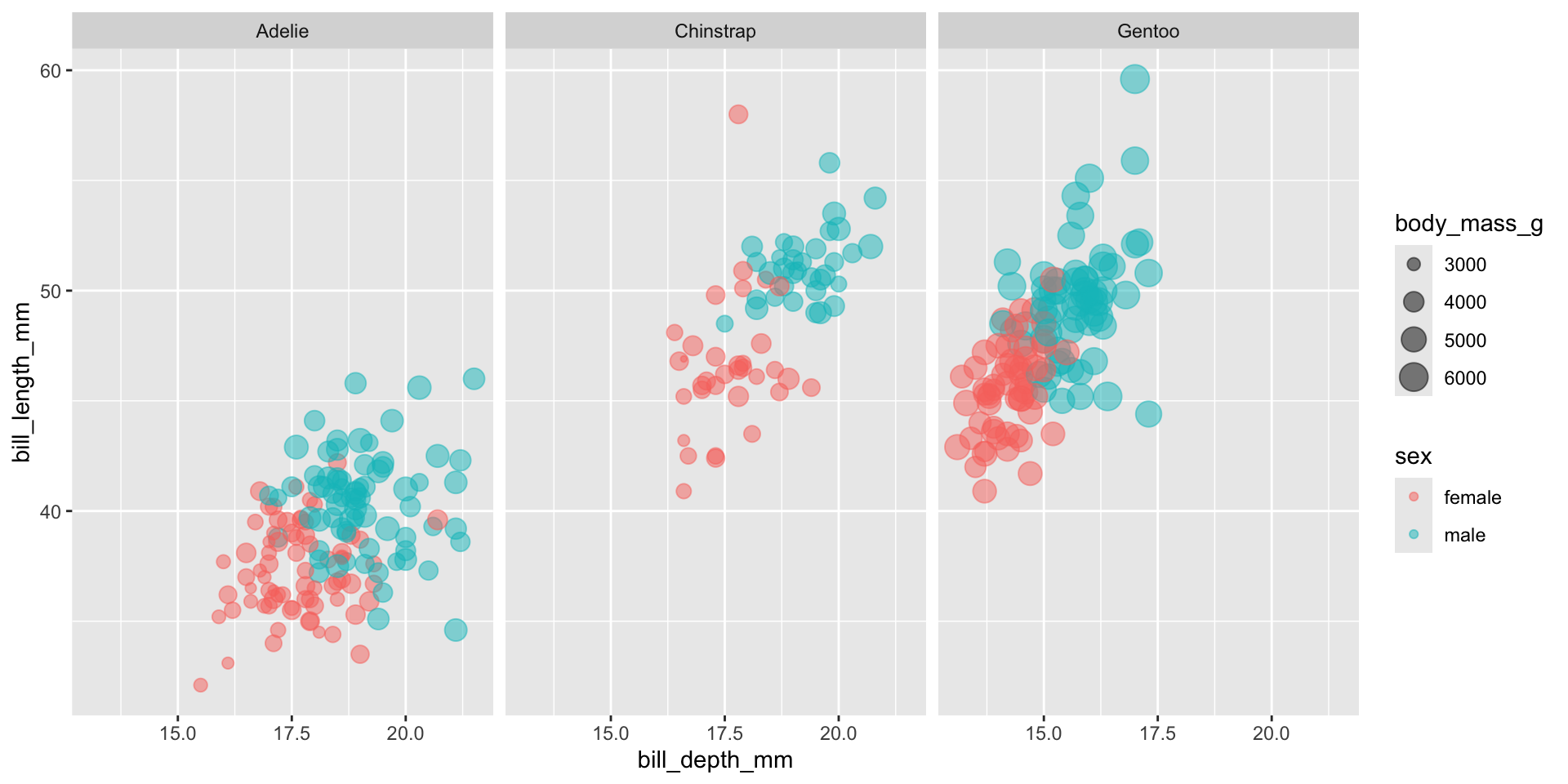
Final plot
- Having learnt that bill depth is our strongest predictor by far (an increase of 1mm for bill depth corresponds to an over 8x higher odds of being male!), we can plot this variable to see how well is segregates
Workshop time!
- These slides and the workshop can be found on the website here:

